Удивительный человек-паук удивителен. В том числе прекрасными английскими словами, которые просочились в мультсериал 94го года от японских аутсорсеров.
Досье на Мистерио
Музей… ну то есть…
Неловко получилось. Болт-ТВ на этом фоне выглядит уже скорее просто забавно )
На днях открыл для себя такую страшную штуку, как дикий туризм!
Собирался — очень долго. Еще в прошлом году закупился всякими необходимыми штуками, но вот так вот бросить уютную квартиру и уехать в неизвестность — собраться не мог очень и очень долго. Казалось, что огромны риски потратить время впустую, приехать куда-то, где будет просто ужасно, не получить никакого удовольствия.
Однако в какой-то момент на мозг стало капать — ну что я не смогу что ли? Да пусть и плохо будет, не развалюсь я от одной ночи в неизвестности! Такая мысль дала нужный пинок в правильном направлении, и заставила собрать вещи и погрузить их на мотик.
К слову, вещей оказалось не так много (это отдельное счастье — ненавижу долгие сборы, но и чувство неподготовленности не дало бы оправиться совсем уж налегке): палатка, коврик надувной внутрипалаточный, коврик обычный полянный, повербанк, 3 бутылки воды (всего 4л), газовая горелка с баллоном, да кастрюлька с ложкой. Отдельным пунктом пошел фотик, так как я подумал, что если уж ехать на озеро, которое я выбирал несколько недель изо всех не сильно далеких от меня озер, то обязательно надо попробовать пофоткать ночью. Во-первых я давно не фоткал ночью в принципе (фотки луны не в счет — очень хотелось пейзажик со звездами забабахать), а во-вторых — ну вдруг мне ТАААК не понравится, думал я, что повторять не захочется, а так хоть фотки может быть будут! Так что в дополнение к вещам-для-жизни пошел и этот ценный груз, включая штатив. К счастью все легко погрузилось на мотик.
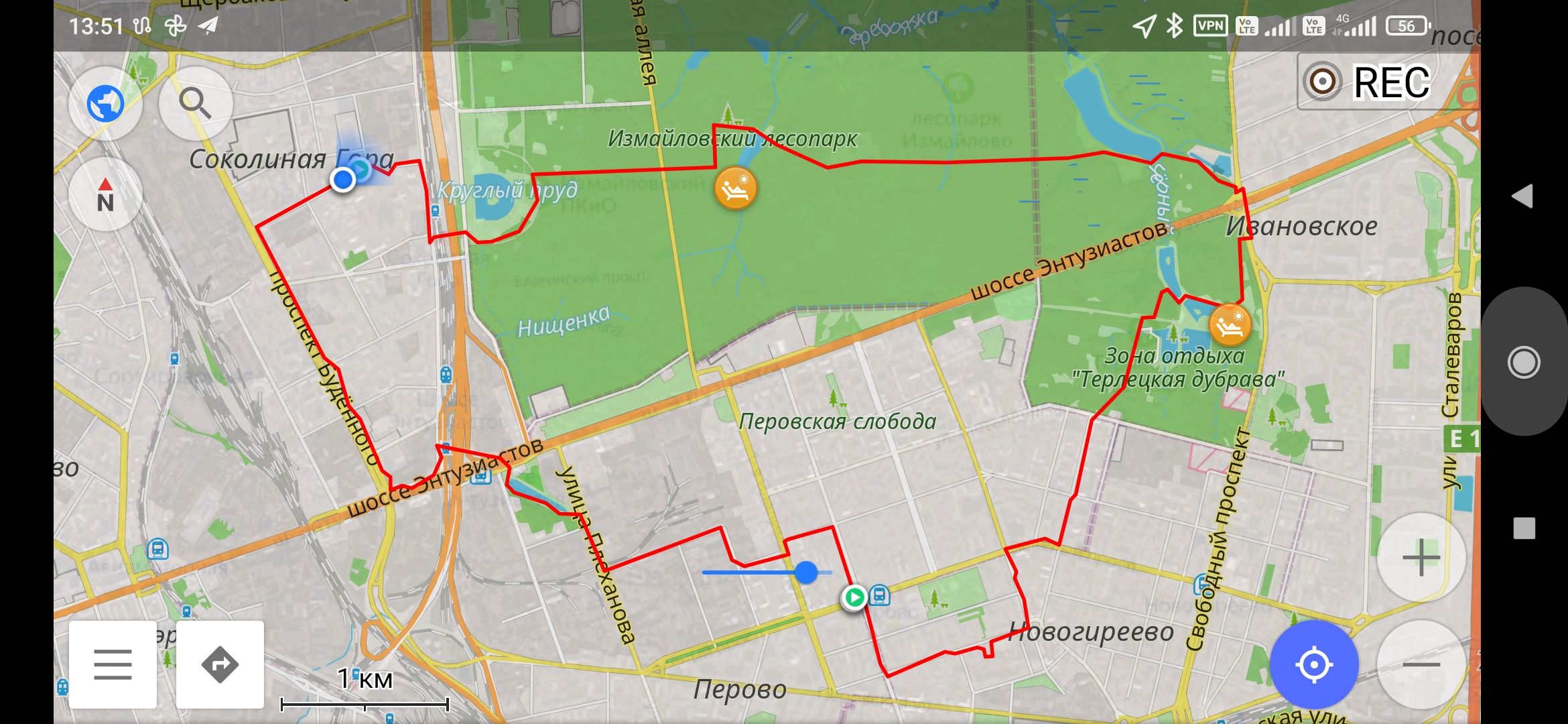
Озеро находилось в паре часов езды по умеренным пробкам дня-вечера субботы. Так что добрался быстро и, к счастью, обнаружил, что места это вполне обжитые, но в тоже время людей мало. Надо сказать, что по самому месту не проезжали машины гугла или яндекса, поэтому все что я смог рассмотреть заранее — кем-то сделанную панорамную фотку с башни островного храма, что на этом озере стоит. И единственный вывод, какой можно было сделать с той панорамы: ну вроде бы не болото. Так что добравшись, я был очень рад, что реальность превзошла ожидания. Хороший берег, спуски к воде, лавочки и места для костра. Забурившись в район третьего-четвертого от края места, с которого открывался хороший вид, я стал раскладываться.
Опять же было много страхов: что если я не разберу/соберу палатку, что если мне не хватит воды, что если горелка не заработает. Но все это уже были мелкие страхи, так как палатку я проверял и знал что ничего сложного там нет, а все возможные проблемы с едой решились бы при помощи магазинчика в местном поселке. Так что это был скорее нервяк, добавляющий приятного адреналина, чем серьезно пугающий =)
Еще одно опасение касалось купания в озере. Фиг знает — вдруг вода отравлена! Поставив палатку, я плюнул и полез в воду — после поездки было довольно жарко, а в воде кто-то уже купался. «А если они с крыши прыгнут — ты тоже прыгнешь?» Я прыгнул ))
Негативный опыт, который, конечно, тоже был обретен, был сконвентирован в знание: надо брать с собой дополнительный комплект белья. Приехал я изрядно мокрый, плавок не брал никаких, так что футболка, носки и трусы оказались в итоге сырыми, и на влажном приозерном воздухе сохнуть просто-напросто отказались. Возможно это не было бы проблемой, если бы я приехал днем, когда еще жарило солнце, но вечером это уже не работало. Но после купания я об этом еще не знал, так что запалил горелку и наварил каши. Так много, что и на утро хватило )) Готовить, даже такую примитивную еду, на природе — кайф!
овсянка, сэр!
Пообсыхав, насколько это возможно, я приготовил большой фотик к ночной съемке и полез в палатку — стало постепенно холодать, пришло время досматривать 1й сезон Мандалорца =). К слову, на вечер мне, в принципе, хватило моего повербанка, но в будущем надо брать пару, чтобы не думать о том, что электричества впритык (хотя в качестве запасного варианта у меня был мотик с USB, но в палатку его взять сложно =)
вид из палатки
Концептуальная ошибка номер два: я не взял с собой одеялко. Опять же подумал, что места на мотике не так много, ну чего я не переживу одну ночь что ли? Пережил, но вкупе с мокрой одеждой (носки я даже снял в итоге, повесив внутри палатки сохнуть хоть как) отсутствие одеяла усилило промерзание, хотя температура воздуха вряд ли падала ниже 18-20 градусов. Вероятно сказалась сырость. Также я тупанул и довольно долго держал палатку закрытой только на сетку, которая спасала от комаров (которых вечером, кстати, почти и не было), но замечательно выпускала все тепло. Закройся я пораньше, думаю к ночи я бы нормально «надышал», так как в конечном счете я таки смог согреться настолько, чтобы заснуть. Но перед этим пришлось выползти и с неудовольствием заметить тучку, которая хоть не сделала дождя, но звезды заслонила. Так что звездной ночной фотки не вышло, вышла просто ночная =)
К счастью В ЦЕЛОМ я уже был скорее доволен поездкой, чем наоборот, так что тучка не сильно испортила мне настроение. Может еще доведется повторить попытку =) Зато на утро, которое для меня настало около 4х часов (поспал я в итоге часа 3 от силы), я стал свидетелем годного тумана, фотка с которым открывает этот пост. Вот еще видосик =)
Навернув по быстрому каши, я начал собираться. Получилось довольно быстро свернуть и запихать в чехол палатку с ковриком, не забыв при этом никаких запчастей. Разве что в САМОЙ палатке! Защита на спину, на которой я спал, оказалась в заложниках этого здоровенного многослойного бесформенного «пододеяльника» (стирающие люди меня поймут)! Почему же палатка не сворачивается?.. Черт!.. Да где же у нее теперь «вход»?!.. К счастью спасти защиту удалось, и даже успелось сфоткать на телефон нежный рассвет, поймав вид буквально за минуту-две до появления яркого красного солнца.
Погрузив все обратно на мотик, я отправился обратно и уже часа через полтора, пролетев по почти пустым дорогам, был дома.
В общем, свой первый дичайший акт туризма я могу смело признать не таким уж и диким — все оказалось не так страшно, как рисовало воображение из москвы. Единение с природой почувствовано, оргвыводы сделаны, компактное одеяло уже заказано и обязательно будет протестировано. Трусы, носки и прочие повербанки — будут захвачены в нужных количествах. А людям, своим примером сподвигшим мою ленивую жопу отправиться в такое приключение, еще не раз икнется моей благодарностью за вдохновение и такой интересный опыт =)
лежишь, такой, на коврике, перед тобой вода, и ветер в деревьях шумит — благодать =)
ЗЫ: А самое страшное в приключении — кот. Который начал топать возле палатки ночью, заставляя думать о не менее чем забредшем в гости медведе-мутанте, готовом НАПАСТЬ! Пришлось выглянуть и убедиться в совершенной мирности гостя )
Уже лет 15 пользовался услугами банка Авангард. Немного архаичный, но вполне беспроблемный банк был.
Пару дней назад, совершенно внезапно они блокируют мне карту и доступ в личный кабинет. Звоню в саппорт: да, говорят, действительно заблокировано — идите в офис, пишите заявление на разблокировку. Бред (а если я далеко от офиса, что делать?), но иду. Объясняю ситуацию работнице офиса, пишу с ее слов заявление в свободной форме, что хочу разблокировать доступ в ЛК. Иду домой, по пути звонят — пишите еще заявление на разблокировку карты. Уточняют, что причина блокировки — компрометация данных, без подробностей. Ладно, возвращаюсь в офис, пишу еще 3 заявления: еще одно на разблокировку ЛК по номеру карты (уже не в свободной форме), на разблокировку карты, и еще одно на перевыпуск карты — на случай если просто разблокировать старую они откажутся (что логично, если карта скомпрометирована).
Дальше интереснее. Вчера они звонят и говорят что заявка на перевыпуск карты принята, ждите когда сделаем ее. Сегодня звонят и сообщают, что банк принял решение о невозможности продолжения сотрудничества со мной (но почему — они не скажут), и мне рекомендуется пойти в офис и написать заявление о расторжении договора. Просто ебануться. То есть иди нахуй, дорогой товарищ, но почему туда — это большой наш секрет.
Что могу сказать, хороший был банк, но с таким отношением к клиентам идет он в том же направлении сам.
В последнее время стал активно ходить — в моем возрасте ужо надо думать о песке здоровье. Сегодня, кажется, рекорд. 23к шагов, ~18 км за 4-часовую прогулку. Ноги гудят, чувство морального удовлетворения — присутствует =))
Навалю еще фоточек, собранных за последние прогулки!
Поимел тут дамп базы данных — текстовик на 40 гигов.
Для понимания проблемы: дамп состоит из двух основных блоков
[блок команд создания таблиц]
[блок команд вставки строк]
Первый блок небольшой, на 150 строк. Второй – все остальные гиги, которые выглядят как
INSERT INTO tablename VALUES (val1, val2… valN);
INSERT INTO tablename VALUES (val1, val2… valN);
...
INSERT INTO tablename VALUES (val1, val2… valN);
Импортируется обычно все командой
cat dump.sql | mysql basename
то есть файл просто читается в пайп и mysql выполняет команды из него.
И в чем подстава.
Во-первых у дампа в начале не хватало пары команд — это выяснилось сразу при попытке импорта и легко выгуглилось. Во-вторых — в блоке импорта строк, ВО ВСЕХ строках отсутствовало начало: «INSERT INTO tablename VALUES»
Я не нашел такой чудо-редактор, который смог бы на редактирование хотя бы открыть этот мегадамп, поэтому к сути.
Сделал два вспомогательных файла:
1.sql – с недостающими командами,
2.sql – с первыми 150 строками, которые про создание таблиц, и первым недостающим «INSERT INTO tablename VALUES» — для начала блока импорта — который я добавил вручную.
Свел задачу к:
— как бы в один поток прочитать сначала эти два файла,
— а потом третий – только в нем пропустить первые строки, а во оставшихся — заменять концы строк с «);» на «); INSERT INTO tablename VALUES», чтобы каждая новая строка начиналась с корректной команды,
— и все это точно также запихать в пайп и отдать mysql.
Оказывается есть такая магия!
{cat 1.sql 2.sql; sed -n -e 's/);/); INSERT INTO tablename VALUES /g;151,$ p' dump.sql;} | mysql basename
конструкция команд внутри {} дает общий вывод, который можно направить в пайп и в mysql.
cat 1.sql 2.sql - просто читает два файла подряд
чтение основного файла отдаем седу, с двумя его командами
sed -n -e 's/);/); INSERT INTO tablename VALUES /g;152,$ p' dump.sql;
здесь ^-- меняем ";)" на "); INSERT..." --^ ^-- --^ - выводим файл со 151 строки
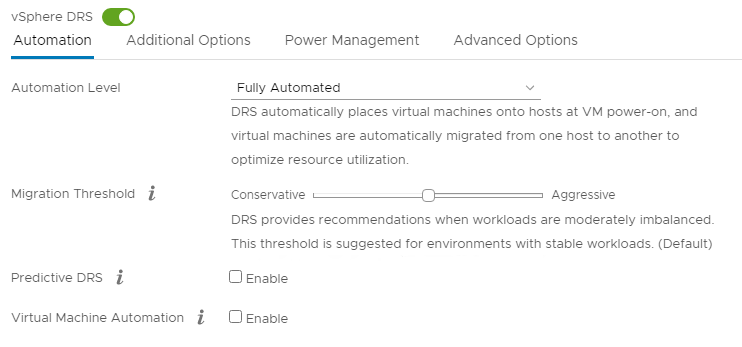
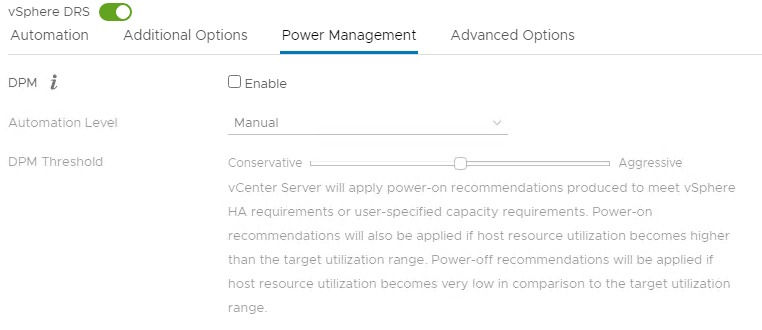
Долго не мог понять почему возникает сабжевая ошибка. В норме, при включенном vSphere DRS виртуальные машины должны автоматически перекидываться на хосты, на которых непосредственно лежат их файлы (если точнее, симпливити дублирует каждую виртуалку, так чтобы 2 хоста имели полный локальный доступ к ней). В моем же случае виртуалки балансировались классически — по загруженности хостов, то есть vmotion работал, но по какой-то причине игнорировал симпливитийную привязку к хранилищу.
Оказалось, причина была в установленной галке «For availability, distribute a more even number of virtual machines across hosts» в настройках vSphere DRS. Вероятно задача равномерного распределения оказалась приоритетнее и полностью отрубила балансировку по доступу к хранилищу. Вывод: если возникла подобная проблема — стоит начать с того чтобы выставить дефолтные настройки DRS
Также могу порекомендовать цикл постов о принципах работы Simplivity: