
Допустим встала задача заменить диск в рейде BTRFS. Замена может быть плановой, когда диск начал активно ругаться через SMART, или аварийной, когда диск уже умер. Рассмотрим случай, когда у нас нет свободных портов для подключения еще одного диска к существующим, и даже для плановой замены нам потребуется сначала извлечь заменяемый диск. Тогда оба сценария у нас будут максимально похожи, и будут сопряжены с выключением сервера.
Итак.
- Если замена плановая (если сервер уже упал переходим к п.2), то лучше сразу в /etc/fstab добавить опцию монтирования degraded ко всем точкам монтирования, которые будут затронуты при изъятии диска.
- UUID="b8022e27-2df2-404d-a404-1ca03f9c90e9" / btrfs defaults,degraded,subvol=@rootfs,noatime,compress-force=zstd 0 0
- UUID="b8022e27-2df2-404d-a404-1ca03f9c90e9" /var/log btrfs defaults,degraded,subvol=@var-log,compress-force=zstd 0 0
- UUID="ea4980c5-dee0-49e0-960c-3975a70f77eb" /share btrfs defaults,degraded,noatime,nofail 0 0
В данном примере физические диски разбиты на разделы, и из разделов составлены RAID1 для «/» и «/var/log» (два сабволюма на общей ФС) и RAID5 для /share (вторая независимая ФС). Таким образом при изъятии диска оба рейда деградируют, и для обоих нужно добавить данную опцию монтирования.
- Выключаем сервер и меняем диск на новый
- При загрузке нажимаем «e» чтобы отредактировать конфигурацию загрузчика. Находим строчку «linux….» как на скриншоте ниже.
* Если рутовый раздел монтируется из сабволюма, т.е. как в п.1 в fstab в параметрах монтирования указана опция «subvol=» с именем сабволюма, то и в строке загрузчика уже будет опция «rootflags=…» в которой эта опция будет повторена — как на скриншоте. В этом случае просто дописываем «,degraded».
* В том случае, если рутовый раздел монтируется из корня самой файловой системы (в п.1 так монтируется /share — параметр «subvol=» при этом отсутствует), то скорее всего в загрузчике в принципе будет отсутствовать опция «rootflags» и ее нужно будет добавить в виде «rootflags=degraded»
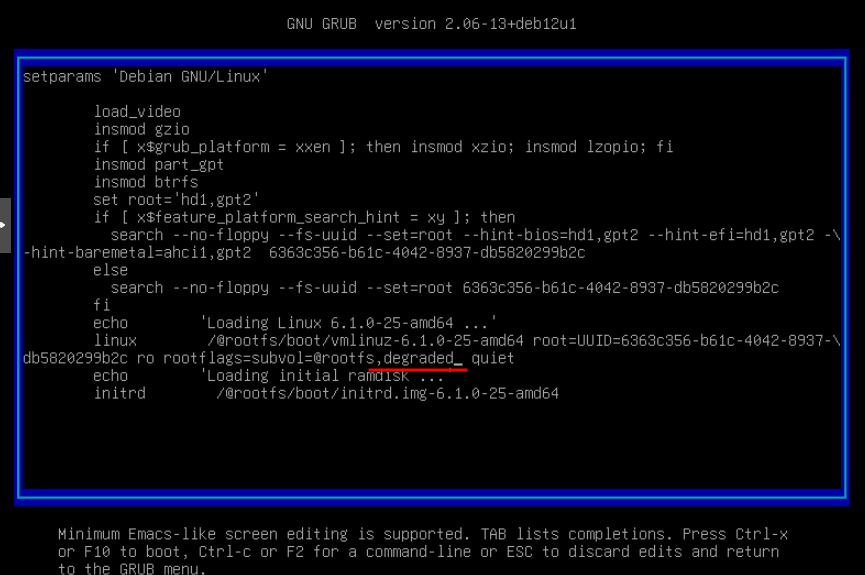
- Нажимаем F10 и загружаемся с указанными опциями загрузчика.
- Если мы на первом шаге не исправили /etc/fstab, то наш сервер не загрузится и предложит перейти в maintenance mode. Делаем это, после чего правим /etc/fstab как в п.1. После этого монтируем разделы командой «mount -a».
Если все прошло удачно и разделы смонтировались — я рекомендовал бы перезагрузить сервер, снова повторить п.п. 3-4, и тем самым добиться полноценной загрузки сервера на деградированных рейдах. Таким образом дальнейшие шаги по пересборке рейда, которые могут быть довольно протяженными по времени, будут проходить при работающем сервере. С другой стороны если вам важны данные, вы хотите снизить нагрузку на диски, и вам не так важно чтобы сервер продолжал быть в работе, можете перейти к следующему пункту сразу после успешного монтирования ваших разделов. - Выполните команду lsblk и убедитесь что все ваши диски видны (на скриншоте диски sda, sdb и sdc — рабочие, sdd — новый, не размеченный диск того же размера)
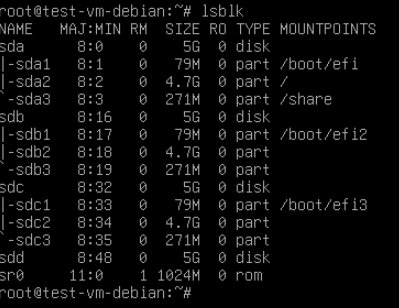
- Копируем таблицу разделов с одного из рабочих дисков на новый
- sfdisk -d /dev/sda | sfdisk /dev/sdd
- Дальше нужно посмотреть конфигурацию btrfs и выяснить какой диск, с ее точки зрения, у нас отсутствует. Выполняем команду
- btrfs fi sh
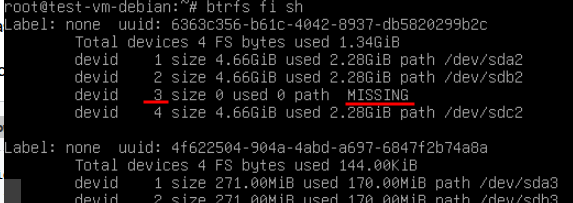 В данном случае отсутствует диск 3, а сам рейд составлен из разделов sda2, sdb2 и sdc2
В данном случае отсутствует диск 3, а сам рейд составлен из разделов sda2, sdb2 и sdc2 - Производим замену: вместо пропавшего диска 3 подставляем раздел нового диска — sdd2
- btrfs replace start 3 /dev/sdd2 /
- Для отслеживания прогресса выполняем команду
- btrfs replace status /
Также можно отметить, что до окончания операции замены в рейде будут видны оба диска — missing и новый
- btrfs fi sh /
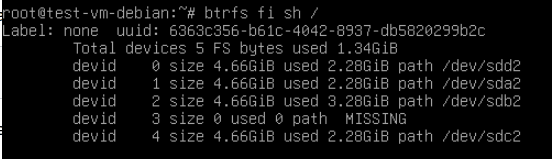
- После завершения замены обязательно производим мягкий ребаланс, так как часть данных на текущий момент скорее всего не будет соответствовать уровню рейда (иными словами не будет задублирована и защищена избыточностью). Для этого сначала смотрим какие профили используются для данных и для метаданных:
- btrfs fi us /
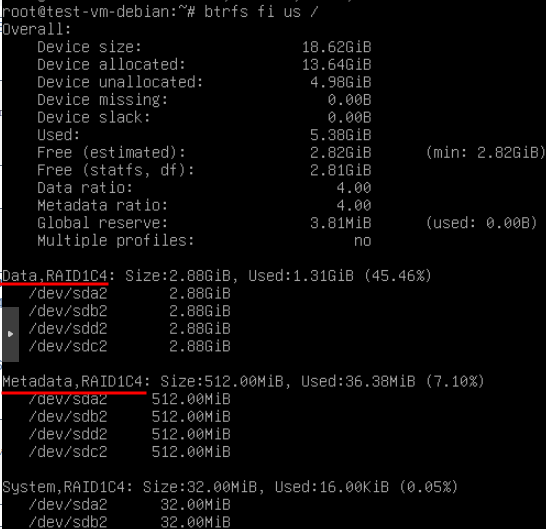
После чего выполняем команду:- btrfs balance start -dconvert=RAID1C4,soft -mconvert=RAID1C4,soft /
dconvert — профиль для данных (Data)
mconvert — профиль для медатанных (Metadata) - Повторяем п.п. 8-11 для всех оставшихся отдельных файловых систем (в данном примере: для ФС, монтируемой в /share, и расположенной на разделах sda3, sdb3 и sdc3).
- Редактируем /etc/fstab, удаляя добавленные ранее опции dagraded.
После этого останется восстановить загрузчик на новом диске, если он там был, и перезагрузить сервер, чтобы убедиться что все работает как надо без дополнительных опций.

 Уже давно сижу на облегченном дебиане, собранном с минимальной инсталляции. В процессе эксплуатации набралось шпаргалок по сборке системы моей мечты, которые записывались в файлик, а теперь перенесены в чуть более развернутом виде сюда на сайт.
Уже давно сижу на облегченном дебиане, собранном с минимальной инсталляции. В процессе эксплуатации набралось шпаргалок по сборке системы моей мечты, которые записывались в файлик, а теперь перенесены в чуть более развернутом виде сюда на сайт.