#!/usr/bin/env python
# -*- coding: utf-8 -*-
# OpenSubtitlesDownload.py / Version 4.1
# This software is designed to help you find and download subtitles for your favorite videos!
# You can browse the project's GitHub page:
# https://github.com/emericg/OpenSubtitlesDownload
# Learn much more about OpenSubtitlesDownload.py on its wiki:
# https://github.com/emericg/OpenSubtitlesDownload/wiki
# You can also browse the official website:
# https://emeric.io/OpenSubtitlesDownload
# Copyright (c) 2020 by Emeric GRANGE <emeric.grange@gmail.com>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
# Contributors / special thanks:
# Thiago Alvarenga Lechuga <thiagoalz@gmail.com> for his work on the 'Windows CLI' and the 'folder search'
# jeroenvdw for his work on the 'subtitles automatic selection' and the 'search by filename'
# Gui13 for his work on the arguments parsing
# Tomáš Hnyk <tomashnyk@gmail.com> for his work on the 'multiple language' feature
# Carlos Acedo <carlos@linux-labs.net> for his work on the original script
import os
import re
import sys
import time
import gzip
import struct
import argparse
import mimetypes
import subprocess
if sys.version_info >= (3, 0):
import shutil
import urllib.request
from xmlrpc.client import ServerProxy, Error
else: # python2
import urllib
from xmlrpclib import ServerProxy, Error
# ==== Opensubtitles.org server settings =======================================
# XML-RPC server domain for opensubtitles.org:
osd_server = ServerProxy('https://api.opensubtitles.org/xml-rpc')
# You can use your opensubtitles.org account to avoid "in-subtitles" advertisment
# and bypass download limits. Be careful about your password security, it will be
# stored right here in plain text... You can also change opensubtitles.org language,
# it will be used for error codes and stuff.
osd_username = ''
osd_password = ''
osd_language = 'en'
# ==== Language settings =======================================================
# 1/ Change the search language by using any supported 3-letter (ISO 639-2) language codes:
# > Supported ISO codes: https://www.opensubtitles.org/addons/export_languages.php
# 2/ Search for subtitles in several languages at once by using multiple codes separated by a comma:
# > Exemple: opt_languages = ['eng,fre']
opt_languages = ['eng']
# Write 2-letter language code (ex: _en) at the end of the subtitles file. 'on', 'off' or 'auto'.
# If you are regularly searching for several language at once, you sould use 'on'.
opt_language_suffix = 'auto'
opt_language_separator = '_'
# ==== Search settings =========================================================
# Subtitles search mode. Can be overridden at run time with '-s' argument.
# - hash (search by hash)
# - filename (search by filename)
# - hash_then_filename (search by hash, then filename if no results)
# - hash_and_filename (search using both methods)
opt_search_mode = 'hash_then_filename'
# Search and download a subtitles even if a subtitles file already exists.
opt_search_overwrite = 'on'
# Subtitles selection mode. Can be overridden at run time with '-t' argument.
# - manual (always let you choose the subtitles you want)
# - default (in case of multiple results, let you choose the subtitles you want)
# - auto (automatically select the best subtitles found)
opt_selection_mode = 'default'
# Customize subtitles download path. Can be overridden at run time with '-o' argument.
# By default, subtitles are downloaded next to their video file.
opt_output_path = ''
# ==== GUI settings ============================================================
# Select your GUI. Can be overridden at run time with '--gui=xxx' argument.
# - auto (autodetection, fallback on CLI)
# - gnome (GNOME/GTK based environments, using 'zenity' backend)
# - kde (KDE/Qt based environments, using 'kdialog' backend)
# - cli (Command Line Interface)
opt_gui = 'auto'
# Change the subtitles selection GUI size:
opt_gui_width = 720
opt_gui_height = 320
# Various GUI options. You can set them to 'on', 'off' or 'auto'.
opt_selection_hi = 'auto'
opt_selection_language = 'auto'
opt_selection_match = 'auto'
opt_selection_rating = 'off'
opt_selection_count = 'off'
# ==== Exit codes ==============================================================
# Exit code returned by the software. You can use them to improve scripting behaviours.
# 0: Success, and subtitles downloaded
# 1: Success, but no subtitles found
# 2: Failure
# ==== Super Print =============================================================
# priority: info, warning, error
# title: only for zenity and kdialog messages
# message: full text, with tags and breaks (tags will be cleaned up for CLI)
def superPrint(priority, title, message):
"""Print messages through terminal, zenity or kdialog"""
if opt_gui == 'gnome':
subprocess.call(['zenity', '--width=' + str(opt_gui_width), '--' + priority, '--title=' + title, '--text=' + message])
elif opt_gui == 'kde':
# Adapt to kdialog
message = message.replace("\n", "<br>")
message = message.replace('\\"', '"')
if priority == 'warning':
priority = 'sorry'
elif priority == 'info':
priority = 'msgbox'
subprocess.call(['kdialog', '--geometry=' + str(opt_gui_width) + 'x' + str(opt_gui_height), '--title=' + title, '--' + priority + '=' + message])
else:
# Clean up formating tags from the zenity messages
message = message.replace("\n\n", "\n")
message = message.replace("<i>", "")
message = message.replace("</i>", "")
message = message.replace("<b>", "")
message = message.replace("</b>", "")
message = message.replace('\\"', '"')
print(">> " + message)
# ==== Check file path & type ==================================================
def checkFileValidity(path):
"""Check mimetype and/or file extension to detect valid video file"""
if os.path.isfile(path) is False:
return False
fileMimeType, encoding = mimetypes.guess_type(path)
if fileMimeType is None:
fileExtension = path.rsplit('.', 1)
if fileExtension[1] not in ['avi', 'mp4', 'mov', 'mkv', 'mk3d', 'webm', \
'ts', 'mts', 'm2ts', 'ps', 'vob', 'evo', 'mpeg', 'mpg', \
'm1v', 'm2p', 'm2v', 'm4v', 'movhd', 'movx', 'qt', \
'mxf', 'ogg', 'ogm', 'ogv', 'rm', 'rmvb', 'flv', 'swf', \
'asf', 'wm', 'wmv', 'wmx', 'divx', 'x264', 'xvid']:
#superPrint("error", "File type error!", "This file is not a video (unknown mimetype AND invalid file extension):\n<i>" + path + "</i>")
return False
else:
fileMimeType = fileMimeType.split('/', 1)
if fileMimeType[0] != 'video':
#superPrint("error", "File type error!", "This file is not a video (unknown mimetype):\n<i>" + path + "</i>")
return False
return True
# ==== Check for existing subtitles file =======================================
def checkSubtitlesExists(path):
"""Check if a subtitles already exists for the current file"""
for ext in ['srt', 'sub', 'sbv', 'smi', 'ssa', 'ass', 'usf']:
subPath = path.rsplit('.', 1)[0] + '.' + ext
if os.path.isfile(subPath) is True:
superPrint("info", "Subtitles already downloaded!", "A subtitles file already exists for this file:\n<i>" + subPath + "</i>")
return True
# With language code? Only check the first language (and probably using the wrong language suffix format)
if opt_language_suffix in ('on', 'auto'):
if len(opt_languages) == 1:
splitted_languages_list = opt_languages[0].split(',')
else:
splitted_languages_list = opt_languages
subPath = path.rsplit('.', 1)[0] + opt_language_separator + splitted_languages_list[0] + '.' + ext
if os.path.isfile(subPath) is True:
superPrint("info", "Subtitles already downloaded!", "A subtitles file already exists for this file:\n<i>" + subPath + "</i>")
return True
return False
# ==== Hashing algorithm =======================================================
# Info: https://trac.opensubtitles.org/projects/opensubtitles/wiki/HashSourceCodes
# This particular implementation is coming from SubDownloader: https://subdownloader.net
def hashFile(path):
"""Produce a hash for a video file: size + 64bit chksum of the first and
last 64k (even if they overlap because the file is smaller than 128k)"""
try:
longlongformat = 'Q' # unsigned long long little endian
bytesize = struct.calcsize(longlongformat)
fmt = "<%d%s" % (65536//bytesize, longlongformat)
f = open(path, "rb")
filesize = os.fstat(f.fileno()).st_size
filehash = filesize
if filesize < 65536 * 2:
superPrint("error", "File size error!", "File size error while generating hash for this file:\n<i>" + path + "</i>")
return "SizeError"
buf = f.read(65536)
longlongs = struct.unpack(fmt, buf)
filehash += sum(longlongs)
f.seek(-65536, os.SEEK_END) # size is always > 131072
buf = f.read(65536)
longlongs = struct.unpack(fmt, buf)
filehash += sum(longlongs)
filehash &= 0xFFFFFFFFFFFFFFFF
f.close()
returnedhash = "%016x" % filehash
return returnedhash
except IOError:
superPrint("error", "I/O error!", "Input/Output error while generating hash for this file:\n<i>" + path + "</i>")
return "IOError"
# ==== GNOME selection window ==================================================
def selectionGnome(subtitlesList):
"""GNOME subtitles selection window using zenity"""
subtitlesSelected = ''
subtitlesItems = ''
subtitlesMatchedByHash = 0
subtitlesMatchedByName = 0
columnHi = ''
columnLn = ''
columnMatch = ''
columnRate = ''
columnCount = ''
# Generate selection window content
for item in subtitlesList['data']:
if item['MatchedBy'] == 'moviehash':
subtitlesMatchedByHash += 1
else:
subtitlesMatchedByName += 1
subtitlesItems += '"' + item['SubFileName'] + '" '
if opt_selection_hi == 'on':
columnHi = '--column="HI" '
if item['SubHearingImpaired'] == '1':
subtitlesItems += '"✔" '
else:
subtitlesItems += '"" '
if opt_selection_language == 'on':
columnLn = '--column="Language" '
subtitlesItems += '"' + item['LanguageName'] + '" '
if opt_selection_match == 'on':
columnMatch = '--column="MatchedBy" '
if item['MatchedBy'] == 'moviehash':
subtitlesItems += '"HASH" '
else:
subtitlesItems += '"" '
if opt_selection_rating == 'on':
columnRate = '--column="Rating" '
subtitlesItems += '"' + item['SubRating'] + '" '
if opt_selection_count == 'on':
columnCount = '--column="Downloads" '
subtitlesItems += '"' + item['SubDownloadsCnt'] + '" '
if subtitlesMatchedByName == 0:
tilestr = ' --title="Subtitles for: ' + videoTitle + '"'
textstr = ' --text="<b>Video title:</b> ' + videoTitle + '\n<b>File name:</b> ' + videoFileName + '"'
elif subtitlesMatchedByHash == 0:
tilestr = ' --title="Subtitles for: ' + videoFileName + '"'
textstr = ' --text="Search results using file name, NOT video detection. <b>May be unreliable...</b>\n<b>File name:</b> ' + videoFileName + '" '
else: # a mix of the two
tilestr = ' --title="Subtitles for: ' + videoTitle + '"'
textstr = ' --text="Search results using file name AND video detection.\n<b>Video title:</b> ' + videoTitle + '\n<b>File name:</b> ' + videoFileName + '"'
# Spawn zenity "list" dialog
process_subtitlesSelection = subprocess.Popen('zenity --width=' + str(opt_gui_width) + ' --height=' + str(opt_gui_height) + ' --list' + tilestr + textstr \
+ ' --column="Available subtitles" ' + columnHi + columnLn + columnMatch + columnRate + columnCount + subtitlesItems, shell=True, stdout=subprocess.PIPE)
# Get back the result
result_subtitlesSelection = process_subtitlesSelection.communicate()
# The results contain a subtitles?
if result_subtitlesSelection[0]:
if sys.version_info >= (3, 0):
subtitlesSelected = str(result_subtitlesSelection[0], 'utf-8').strip("\n")
else: # python2
subtitlesSelected = str(result_subtitlesSelection[0]).strip("\n")
# Hack against recent zenity version?
if len(subtitlesSelected.split("|")) > 1:
if subtitlesSelected.split("|")[0] == subtitlesSelected.split("|")[1]:
subtitlesSelected = subtitlesSelected.split("|")[0]
else:
if process_subtitlesSelection.returncode == 0:
subtitlesSelected = subtitlesList['data'][0]['SubFileName']
# Return the result
return subtitlesSelected
# ==== KDE selection window ====================================================
def selectionKde(subtitlesList):
"""KDE subtitles selection window using kdialog"""
subtitlesSelected = ''
subtitlesItems = ''
subtitlesMatchedByHash = 0
subtitlesMatchedByName = 0
# Generate selection window content
# TODO doesn't support additional columns
index = 0
for item in subtitlesList['data']:
if item['MatchedBy'] == 'moviehash':
subtitlesMatchedByHash += 1
else:
subtitlesMatchedByName += 1
# key + subtitles name
subtitlesItems += str(index) + ' "' + item['SubFileName'] + '" '
index += 1
if subtitlesMatchedByName == 0:
tilestr = ' --title="Subtitles for ' + videoTitle + '"'
menustr = ' --menu="<b>Video title:</b> ' + videoTitle + '<br><b>File name:</b> ' + videoFileName + '" '
elif subtitlesMatchedByHash == 0:
tilestr = ' --title="Subtitles for ' + videoFileName + '"'
menustr = ' --menu="Search results using file name, NOT video detection. <b>May be unreliable...</b><br><b>File name:</b> ' + videoFileName + '" '
else: # a mix of the two
tilestr = ' --title="Subtitles for ' + videoTitle + '" '
menustr = ' --menu="Search results using file name AND video detection.<br><b>Video title:</b> ' + videoTitle + '<br><b>File name:</b> ' + videoFileName + '" '
# Spawn kdialog "radiolist"
process_subtitlesSelection = subprocess.Popen('kdialog --geometry=' + str(opt_gui_width) + 'x' + str(opt_gui_height) + tilestr + menustr + subtitlesItems, shell=True, stdout=subprocess.PIPE)
# Get back the result
result_subtitlesSelection = process_subtitlesSelection.communicate()
# The results contain the key matching a subtitles?
if result_subtitlesSelection[0]:
if sys.version_info >= (3, 0):
keySelected = int(str(result_subtitlesSelection[0], 'utf-8').strip("\n"))
else: # python2
keySelected = int(str(result_subtitlesSelection[0]).strip("\n"))
subtitlesSelected = subtitlesList['data'][keySelected]['SubFileName']
# Return the result
return subtitlesSelected
# ==== CLI selection mode ======================================================
def selectionCLI(subtitlesList):
"""Command Line Interface, subtitles selection inside your current terminal"""
subtitlesIndex = 0
subtitlesItem = ''
# Print video infos
print("\n>> Title: " + videoTitle)
print(">> Filename: " + videoFileName)
# Print subtitles list on the terminal
print(">> Available subtitles:")
for item in subtitlesList['data']:
subtitlesIndex += 1
subtitlesItem = '"' + item['SubFileName'] + '" '
if opt_selection_hi == 'on' and item['SubHearingImpaired'] == '1':
subtitlesItem += '> "HI" '
if opt_selection_language == 'on':
subtitlesItem += '> "Language: ' + item['LanguageName'] + '" '
if opt_selection_match == 'on':
subtitlesItem += '> "MatchedBy: ' + item['MatchedBy'] + '" '
if opt_selection_rating == 'on':
subtitlesItem += '> "SubRating: ' + item['SubRating'] + '" '
if opt_selection_count == 'on':
subtitlesItem += '> "SubDownloadsCnt: ' + item['SubDownloadsCnt'] + '" '
if item['MatchedBy'] == 'moviehash':
print("\033[92m[" + str(subtitlesIndex) + "]\033[0m " + subtitlesItem)
else:
print("\033[93m[" + str(subtitlesIndex) + "]\033[0m " + subtitlesItem)
# Ask user selection
print("\033[91m[0]\033[0m Cancel search")
sub_selection = -1
while(sub_selection < 0 or sub_selection > subtitlesIndex):
try:
if sys.version_info >= (3, 0):
sub_selection = int(input(">> Enter your choice (0-" + str(subtitlesIndex) + "): "))
else: # python 2
sub_selection = int(raw_input(">> Enter your choice (0-" + str(subtitlesIndex) + "): "))
except:
sub_selection = -1
# Return the result
if sub_selection == 0:
print("Cancelling search...")
return ""
return subtitlesList['data'][sub_selection-1]['SubFileName']
# ==== Automatic selection mode ================================================
def selectionAuto(subtitlesList):
"""Automatic subtitles selection using filename match"""
if len(opt_languages) == 1:
splitted_languages_list = list(reversed(opt_languages[0].split(',')))
else:
splitted_languages_list = opt_languages
videoFileParts = videoFileName.replace('-', '.').replace(' ', '.').replace('_', '.').lower().split('.')
maxScore = -1
for subtitle in subtitlesList['data']:
score = 0
# points to respect languages priority
score += splitted_languages_list.index(subtitle['SubLanguageID']) * 100
# extra point if the sub is found by hash
if subtitle['MatchedBy'] == 'moviehash':
score += 1
# points for filename mach
subFileParts = subtitle['SubFileName'].replace('-', '.').replace(' ', '.').replace('_', '.').lower().split('.')
for subPart in subFileParts:
for filePart in videoFileParts:
if subPart == filePart:
score += 1
if score > maxScore:
maxScore = score
subtitlesSelected = subtitle['SubFileName']
return subtitlesSelected
# ==== Check dependencies ======================================================
def dependencyChecker():
"""Check the availability of tools used as dependencies"""
if opt_gui != 'cli':
if sys.version_info >= (3, 3):
for tool in ['gunzip', 'wget']:
path = shutil.which(tool)
if path is None:
superPrint("error", "Missing dependency!", "The <b>'" + tool + "'</b> tool is not available, please install it!")
return False
return True
# ==============================================================================
# ==== Main program (execution starts here) ====================================
# ==============================================================================
ExitCode = 2
# ==== Argument parsing
# Get OpenSubtitlesDownload.py script absolute path
if os.path.isabs(sys.argv[0]):
scriptPath = sys.argv[0]
else:
scriptPath = os.getcwd() + "/" + str(sys.argv[0])
# Setup ArgumentParser
parser = argparse.ArgumentParser(prog='OpenSubtitlesDownload.py',
description='Automatically find and download the right subtitles for your favorite videos!',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('--cli', help="Force CLI mode", action='store_true')
parser.add_argument('-g', '--gui', help="Select the GUI you want from: auto, kde, gnome, cli (default: auto)")
parser.add_argument('-l', '--lang', help="Specify the language in which the subtitles should be downloaded (default: eng).\nSyntax:\n-l eng,fre: search in both language\n-l eng -l fre: download both language", nargs='?', action='append')
parser.add_argument('-i', '--skip', help="Skip search if an existing subtitles file is detected", action='store_true')
parser.add_argument('-s', '--search', help="Search mode: hash, filename, hash_then_filename, hash_and_filename (default: hash_then_filename)")
parser.add_argument('-t', '--select', help="Selection mode: manual, default, auto")
parser.add_argument('-a', '--auto', help="Trigger automatic selection and download of the best subtitles found", action='store_true')
parser.add_argument('-o', '--output', help="Override subtitles download path, instead of next their video file")
parser.add_argument('filePathListArg', help="The video file(s) for which subtitles should be searched and downloaded", nargs='+')
# Only use ArgumentParser if we have arguments...
if len(sys.argv) > 1:
result = parser.parse_args()
# Handle results
if result.cli:
opt_gui = 'cli'
if result.gui:
opt_gui = result.gui
if result.search:
opt_search_mode = result.search
if result.skip:
opt_search_overwrite = 'off'
if result.select:
opt_selection_mode = result.select
if result.auto:
opt_selection_mode = 'auto'
if result.output:
opt_output_path = result.output
if result.lang:
if opt_languages != result.lang:
opt_languages = result.lang
opt_selection_language = 'on'
if opt_language_suffix != 'off':
opt_language_suffix = 'on'
# GUI auto detection
if opt_gui == 'auto':
# Note: "ps cax" only output the first 15 characters of the executable's names
ps = str(subprocess.Popen(['ps', 'cax'], stdout=subprocess.PIPE).communicate()[0]).split('\n')
for line in ps:
if ('gnome-session' in line) or ('cinnamon-sessio' in line) or ('mate-session' in line) or ('xfce4-session' in line):
opt_gui = 'gnome'
break
elif 'ksmserver' in line:
opt_gui = 'kde'
break
# Sanitize settings
if opt_search_mode not in ['hash', 'filename', 'hash_then_filename', 'hash_and_filename']:
opt_search_mode = 'hash_then_filename'
if opt_selection_mode not in ['manual', 'default', 'auto']:
opt_selection_mode = 'default'
if opt_gui not in ['gnome', 'kde', 'cli']:
opt_gui = 'cli'
opt_search_mode = 'hash_then_filename'
opt_selection_mode = 'auto'
print("Unknown GUI, falling back to an automatic CLI mode")
# ==== Check for the necessary tools (must be done after GUI auto detection)
if dependencyChecker() is False:
sys.exit(2)
# ==== Get valid video paths
videoPathList = []
if 'result' in locals():
# Go through the paths taken from arguments, and extract only valid video paths
for i in result.filePathListArg:
filePath = os.path.abspath(i)
if os.path.isdir(filePath):
# If it is a folder, check all of its files
for item in os.listdir(filePath):
localPath = os.path.join(filePath, item)
if checkFileValidity(localPath):
videoPathList.append(localPath)
elif checkFileValidity(filePath):
# If it is a valid file, use it
videoPathList.append(filePath)
else:
superPrint("error", "No file provided!", "No file provided!")
sys.exit(2)
# If videoPathList is empty, abort!
if not videoPathList:
parser.print_help()
sys.exit(1)
# Check if the subtitles files already exists
if opt_search_overwrite == 'off':
videoPathList = [path for path in videoPathList if not checkSubtitlesExists(path)]
# If videoPathList is empty, exit!
if not videoPathList:
sys.exit(1)
# ==== Instances dispatcher ====================================================
# The first video file will be processed by this instance
videoPath = videoPathList[0]
videoPathList.pop(0)
# The remaining file(s) are dispatched to new instance(s) of this script
for videoPathDispatch in videoPathList:
# Handle current options
command = sys.executable + " " + scriptPath + " -g " + opt_gui + " -s " + opt_search_mode + " -t " + opt_selection_mode
if not (len(opt_languages) == 1 and opt_languages[0] == 'eng'):
for resultlangs in opt_languages:
command += " -l " + resultlangs
# Split command string
command_splitted = command.split()
# The videoPath filename can contain spaces, but we do not want to split that, so add it right after the split
command_splitted.append(videoPathDispatch)
# Do not spawn too many instances at once
time.sleep(0.33)
if opt_gui == 'cli' and opt_selection_mode != 'auto':
# Synchronous call
process_videoDispatched = subprocess.call(command_splitted)
else:
# Asynchronous call
process_videoDispatched = subprocess.Popen(command_splitted)
# ==== Search and download subtitles ===========================================
try:
# ==== Connection to OpenSubtitlesDownload
try:
session = osd_server.LogIn(osd_username, osd_password, osd_language, 'opensubtitles-download 4.1')
except Exception:
# Retry once after a delay (could just be a momentary overloaded server?)
time.sleep(3)
try:
session = osd_server.LogIn(osd_username, osd_password, osd_language, 'opensubtitles-download 4.1')
except Exception:
superPrint("error", "Connection error!", "Unable to reach opensubtitles.org servers!\n\nPlease check:\n- Your Internet connection status\n- www.opensubtitles.org availability\n- Your downloads limit (200 subtitles per 24h)\n\nThe subtitles search and download service is powered by opensubtitles.org. Be sure to donate if you appreciate the service provided!")
sys.exit(2)
# Connection refused?
if session['status'] != '200 OK':
superPrint("error", "Connection error!", "Opensubtitles.org servers refused the connection: " + session['status'] + ".\n\nPlease check:\n- Your Internet connection status\n- www.opensubtitles.org availability\n- Your downloads limit (200 subtitles per 24h)\n\nThe subtitles search and download service is powered by opensubtitles.org. Be sure to donate if you appreciate the service provided!")
sys.exit(2)
# Count languages marked for this search
searchLanguage = 0
searchLanguageResult = 0
for SubLanguageID in opt_languages:
searchLanguage += len(SubLanguageID.split(','))
searchResultPerLanguage = [searchLanguage]
# ==== Get file hash, size and name
videoTitle = ''
videoHash = hashFile(videoPath)
videoSize = os.path.getsize(videoPath)
videoFileName = os.path.basename(videoPath)
# ==== Search for available subtitles on OpenSubtitlesDownload
for SubLanguageID in opt_languages:
searchList = []
subtitlesList = {}
if opt_search_mode in ('hash', 'hash_then_filename', 'hash_and_filename'):
searchList.append({'sublanguageid':SubLanguageID, 'moviehash':videoHash, 'moviebytesize':str(videoSize)})
if opt_search_mode in ('filename', 'hash_and_filename'):
searchList.append({'sublanguageid':SubLanguageID, 'query':videoFileName})
## Primary search
try:
subtitlesList = osd_server.SearchSubtitles(session['token'], searchList)
except Exception:
# Retry once after a delay (we are already connected, the server may be momentary overloaded)
time.sleep(3)
try:
subtitlesList = osd_server.SearchSubtitles(session['token'], searchList)
except Exception:
superPrint("error", "Search error!", "Unable to reach opensubtitles.org servers!\n<b>Search error</b>")
#if (opt_search_mode == 'hash_and_filename'):
# TODO Cleanup duplicate between moviehash and filename results
## Fallback search
if ((opt_search_mode == 'hash_then_filename') and (('data' in subtitlesList) and (not subtitlesList['data']))):
searchList[:] = [] # searchList.clear()
searchList.append({'sublanguageid':SubLanguageID, 'query':videoFileName})
subtitlesList.clear()
try:
subtitlesList = osd_server.SearchSubtitles(session['token'], searchList)
except Exception:
# Retry once after a delay (we are already connected, the server may be momentary overloaded)
time.sleep(3)
try:
subtitlesList = osd_server.SearchSubtitles(session['token'], searchList)
except Exception:
superPrint("error", "Search error!", "Unable to reach opensubtitles.org servers!\n<b>Search error</b>")
## Parse the results of the XML-RPC query
if ('data' in subtitlesList) and (subtitlesList['data']):
# Mark search as successful
searchLanguageResult += 1
subtitlesSelected = ''
# If there is only one subtitles (matched by file hash), auto-select it (except in CLI mode)
if (len(subtitlesList['data']) == 1) and (subtitlesList['data'][0]['MatchedBy'] == 'moviehash'):
if opt_selection_mode != 'manual':
subtitlesSelected = subtitlesList['data'][0]['SubFileName']
# Get video title
videoTitle = subtitlesList['data'][0]['MovieName']
# Title and filename may need string sanitizing to avoid zenity/kdialog handling errors
if opt_gui != 'cli':
videoTitle = videoTitle.replace('"', '\\"')
videoTitle = videoTitle.replace("'", "\'")
videoTitle = videoTitle.replace('`', '\`')
videoTitle = videoTitle.replace("&", "&")
videoFileName = videoFileName.replace('"', '\\"')
videoFileName = videoFileName.replace("'", "\'")
videoFileName = videoFileName.replace('`', '\`')
videoFileName = videoFileName.replace("&", "&")
# If there is more than one subtitles and opt_selection_mode != 'auto',
# then let the user decide which one will be downloaded
if not subtitlesSelected:
# Automatic subtitles selection?
if opt_selection_mode == 'auto':
subtitlesSelected = selectionAuto(subtitlesList)
else:
# Go through the list of subtitles and handle 'auto' settings activation
for item in subtitlesList['data']:
if opt_selection_match == 'auto':
if opt_search_mode == 'hash_and_filename':
opt_selection_match = 'on'
if opt_selection_language == 'auto':
if searchLanguage > 1:
opt_selection_language = 'on'
if opt_selection_hi == 'auto':
if item['SubHearingImpaired'] == '1':
opt_selection_hi = 'on'
if opt_selection_rating == 'auto':
if item['SubRating'] != '0.0':
opt_selection_rating = 'on'
if opt_selection_count == 'auto':
opt_selection_count = 'on'
# Spaw selection window
if opt_gui == 'gnome':
subtitlesSelected = selectionGnome(subtitlesList)
elif opt_gui == 'kde':
subtitlesSelected = selectionKde(subtitlesList)
else: # CLI
subtitlesSelected = selectionCLI(subtitlesList)
# If a subtitles has been selected at this point, download it!
if subtitlesSelected:
subIndex = 0
subIndexTemp = 0
# Select the subtitles file to download
for item in subtitlesList['data']:
if item['SubFileName'] == subtitlesSelected:
subIndex = subIndexTemp
break
else:
subIndexTemp += 1
subLangId = opt_language_separator + subtitlesList['data'][subIndex]['ISO639']
subLangName = subtitlesList['data'][subIndex]['LanguageName']
subURL = subtitlesList['data'][subIndex]['SubDownloadLink']
subEncoding = subtitlesList['data'][subIndex]['SubEncoding']
subPath = videoPath.rsplit('.', 1)[0] + '.' + subtitlesList['data'][subIndex]['SubFormat']
if opt_output_path and os.path.isdir(os.path.abspath(opt_output_path)):
subPath = os.path.abspath(opt_output_path) + "/" + subPath.rsplit('/', 1)[1]
# Write language code into the filename?
if ((opt_language_suffix == 'on') or (opt_language_suffix == 'auto' and searchLanguageResult > 1)):
subPath = videoPath.rsplit('.', 1)[0] + subLangId + '.' + subtitlesList['data'][subIndex]['SubFormat']
# Escape non-alphanumeric characters from the subtitles path
if opt_gui != 'cli':
subPath = re.escape(subPath)
# Make sure we are downloading an UTF8 encoded file
downloadPos = subURL.find("download/")
if downloadPos > 0:
subURL = subURL[:downloadPos+9] + "subencoding-utf8/" + subURL[downloadPos+9:]
## Download and unzip the selected subtitles (with progressbar)
if opt_gui == 'gnome':
process_subtitlesDownload = subprocess.call("(wget -q -O - " + subURL + " | gunzip > " + subPath + ") 2>&1" + ' | (zenity --auto-close --progress --pulsate --title="Downloading subtitles, please wait..." --text="Downloading <b>' + subtitlesList['data'][subIndex]['LanguageName'] + '</b> subtitles for <b>' + videoTitle + '</b>...")', shell=True)
elif opt_gui == 'kde':
process_subtitlesDownload = subprocess.call("(wget -q -O - " + subURL + " | gunzip > " + subPath + ") 2>&1", shell=True)
else: # CLI
print(">> Downloading '" + subtitlesList['data'][subIndex]['LanguageName'] + "' subtitles for '" + videoTitle + "'")
if sys.version_info >= (3, 0):
tmpFile1, headers = urllib.request.urlretrieve(subURL)
tmpFile2 = gzip.GzipFile(tmpFile1)
byteswritten = open(subPath, 'wb').write(tmpFile2.read())
if byteswritten > 0:
process_subtitlesDownload = 0
else:
process_subtitlesDownload = 1
else: # python 2
tmpFile1, headers = urllib.urlretrieve(subURL)
tmpFile2 = gzip.GzipFile(tmpFile1)
open(subPath, 'wb').write(tmpFile2.read())
process_subtitlesDownload = 0
# If an error occurs, say so
if process_subtitlesDownload != 0:
superPrint("error", "Subtitling error!", "An error occurred while downloading or writing <b>" + subtitlesList['data'][subIndex]['LanguageName'] + "</b> subtitles for <b>" + videoTitle + "</b>.")
osd_server.LogOut(session['token'])
sys.exit(2)
## Print a message if no subtitles have been found, for any of the languages
if searchLanguageResult == 0:
superPrint("info", "No subtitles available :-(", '<b>No subtitles found</b> for this video:\n<i>' + videoFileName + '</i>')
ExitCode = 1
else:
ExitCode = 0
except (OSError, IOError, RuntimeError, TypeError, NameError, KeyError):
# Do not warn about remote disconnection # bug/feature of python 3.5?
if "http.client.RemoteDisconnected" in str(sys.exc_info()[0]):
sys.exit(ExitCode)
# An unknown error occur, let's apologize before exiting
superPrint("error", "Unexpected error!", "OpenSubtitlesDownload encountered an <b>unknown error</b>, sorry about that...\n\n" + \
"Error: <b>" + str(sys.exc_info()[0]).replace('<', '[').replace('>', ']') + "</b>\n" + \
"Line: <b>" + str(sys.exc_info()[-1].tb_lineno) + "</b>\n\n" + \
"Just to be safe, please check:\n- www.opensubtitles.org availability\n- Your downloads limit (200 subtitles per 24h)\n- Your Internet connection status\n- That are using the latest version of this software ;-)")
except Exception:
# Catch unhandled exceptions but do not spawn an error window
print("Unexpected error (line " + str(sys.exc_info()[-1].tb_lineno) + "): " + str(sys.exc_info()[0]))
# Disconnect from opensubtitles.org server, then exit
if session and session['token']:
osd_server.LogOut(session['token'])
sys.exit(ExitCode)



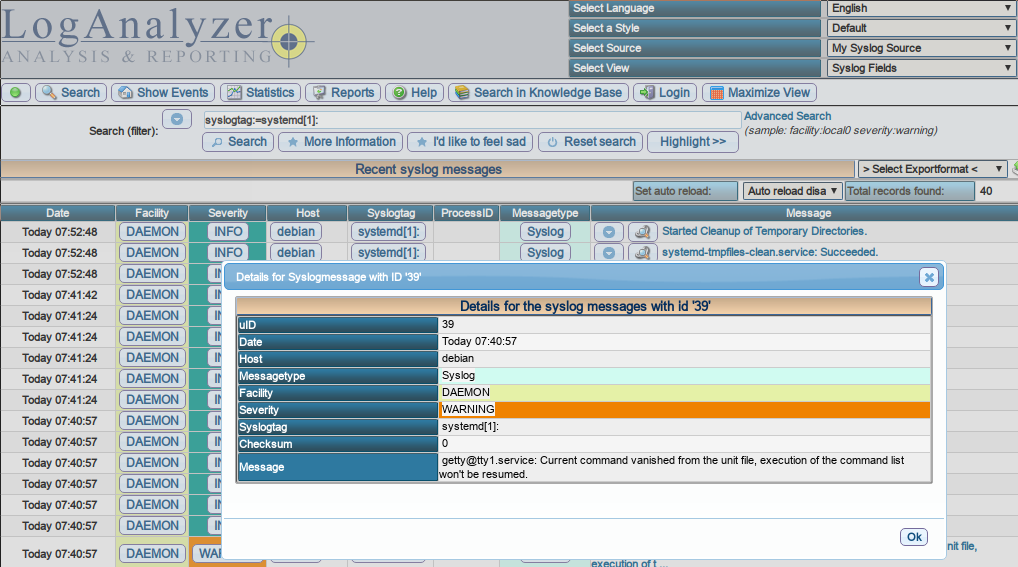
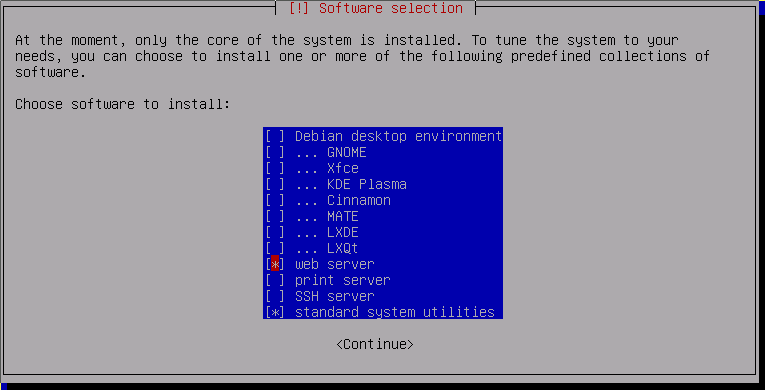
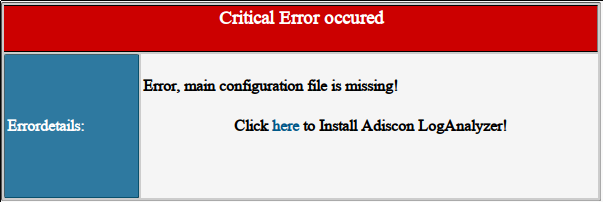
 Невероятно странно, но попытки нагуглить хоть какой-нибудь веб-интерфейс для сислога приводят в основном в дебри топов коммерческих интерфейсов, среди которых, может, и есть бесплатные версии, но будьте любезны сами ковыряться и разбираться насколько оно убого или нет, и какой функционал там порезан.
Невероятно странно, но попытки нагуглить хоть какой-нибудь веб-интерфейс для сислога приводят в основном в дебри топов коммерческих интерфейсов, среди которых, может, и есть бесплатные версии, но будьте любезны сами ковыряться и разбираться насколько оно убого или нет, и какой функционал там порезан.