 Сегодня хочу рассказать о достаточно нетипичном решении для объединения дисков в один массив. Начну с юзкейса.
Сегодня хочу рассказать о достаточно нетипичном решении для объединения дисков в один массив. Начну с юзкейса.
У меня есть домашняя файлопомойка, которая построена на классическим RAID5. Инфа на ней хранится, прямо скажем, не критической важности, но все же я предпочитаю ее иногда бэкапить, чтобы хотя бы копия за прошлый год у меня где-то валялась. Разумеется, мне не хочется тратить большие деньги на бэкапные диски, поэтому, как правило, это старые, относительно небольшого объема, разнокалиберные харды из серии «что было под рукой».
Понятно, что классическим способом получения большого тома из нескольких дисков, является объединение их через LVM, или сборка RAID0. Однако, учитывая,что диски старые и посыпаться могут, например, на этапе восстановления информации с них, мне бы не хотелось рисковать всем таким массивом. Хотелось бы объединить диски в него так, чтобы каждый отдельный диск нес на себе самостоятельную файловую систему, которую можно было бы смонтировать отдельно. Допустим, в массиве из 3х дисков один умер — я смонтировал два оставшихся диска отдельно и спокойно скопировал с них инфу.
Удивительно, но когда я полез гуглить такую хотелку, оказалось, что решение уже придумано и называется mergerfs.
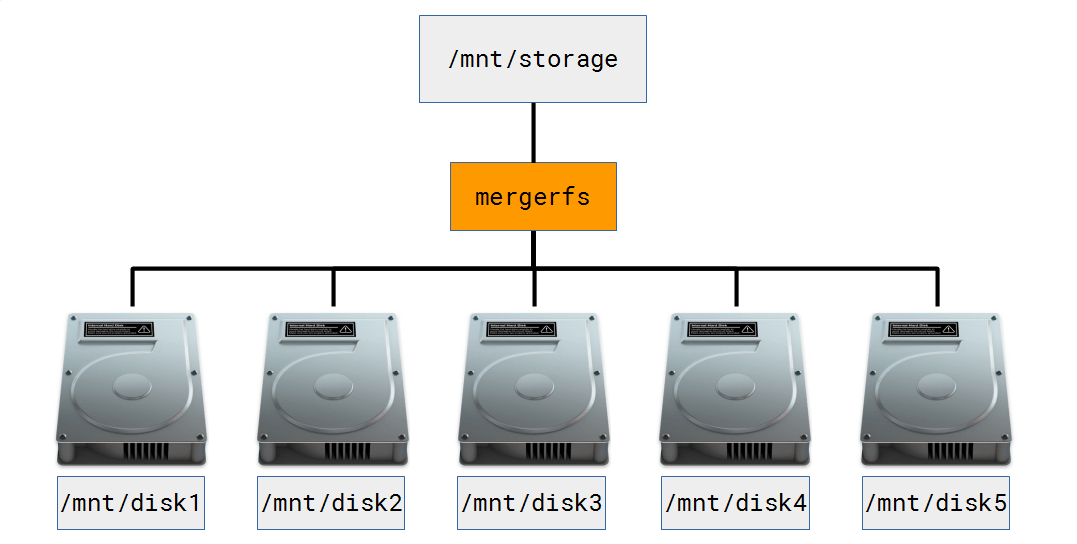
Работает оно ровно так — вы монтируете ваши диски по отдельности, а потом при помощи утилиты mergerfs объединяете их в виртуальную фс.
При этом файлы пишутся то на один диск, то на второй, для балансировки свободного места. При этом любой конкретный файл будет лежать только на одном реальном диске и его можно будет с него прочитать.
Как можно видеть: на одном смонтированном томе виден один файл, на втором — второй, а в точке монтирования mergerfs — оба.
Схема из man mergerfs:
Конечно, нельзя рекомендовать это решение там, где вы имеете надежное оборудование и вам важна скорость — mergerfs работает через fuse, так что в любом случае это компромисс и не замена RAID0. Но в случае подобном моем — это однозначно лучший вариант, который можно придумать.
PS: К слову, mergerfs не единственная виртуальная ФС такого типа. Изначально я наткнутся на mhddfs, которая даже есть в репозитории debian. Однако, как я понял, ее разработка завяла, а вот тут пишут, что в ней есть баги и лучше таки использовать mergerfs.